概念
一个很长的二进制向量,一个二进制数组,由0和1组成,主要作用是判断一个数据存不存在这个于这个数组中,如果不存在就是0,如果存在的话就是1,使用0和1的二进制存储来表示存在的关系。
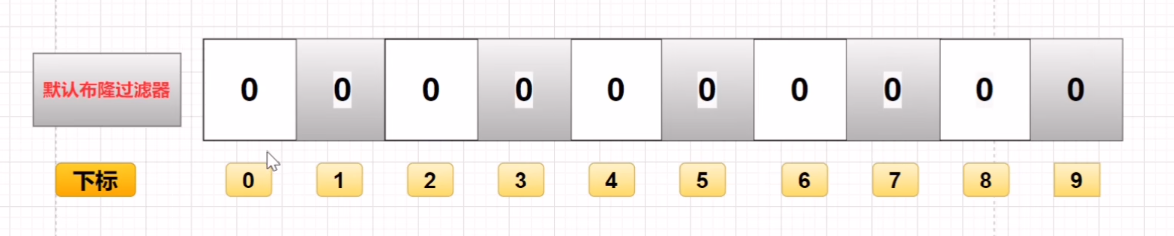
原理
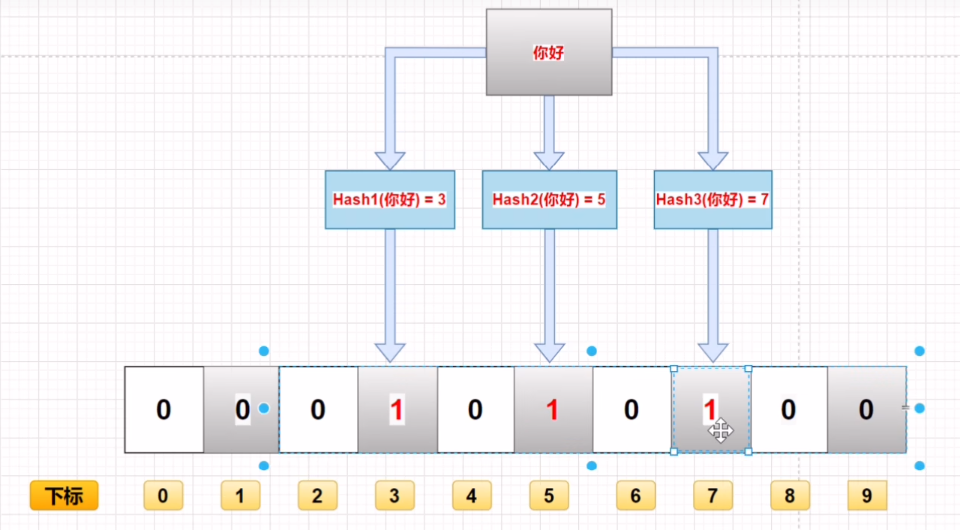
存入过程
经过hash算法对数据进行计算,然后对数组长度进行取模,进而得到他在数组中的位置,然后将该位置的值设置成1
查询过程
经过多个hash算法计算取模后,所有位置的值都是1就是表示这个数据存在,否则就表示这个数据不存在
- 多个hash函数
- 二进制数据必须都是1
删除数据
很难实现删除
可能会出现多个数据计算出的hash取模后的下标位置是同一个位置,即这个位置可能存在多个数据,那么当删除其中一个数据时,可能会导致另一个数据也会被误删。
优点、缺点
优点
- 是由一串二进制数组组成,所以占用空间非常小
- 插入和查询是很快的,因为他是计算数据的hash值,然后再由hash值映射到数组的下标,基于数组的特性,他的查询和插入时很快的,所以他的时间复杂度是o(k),k表示hash函数的个数
- 保密性好,存储的都是二进制数据,本身也不存储原始数据,无法得知0、1的意义是什么
缺点
- 很难实现删除操作
- 存在误判这个数据本身不存在数组中,但是经过一系列计算后,判断这个数据存在于数组中,hash冲突,解决办法是减小误判率,但是不能过小,因为减小误判率是通过增加hash函数实现的,当增加hash函数时,除了会增加计算时间外,因为会出现多个hash结果,他映射到数组中的位置也会增多,空间占用也会增加。为1不一定存在,但是为0一定不存在。
解决缓存穿透
当大量数据访问一个不存在于缓存中的数据,导致请求直接访问后端存储(如数据库),并且由于数据不存在,这个请求在缓存和后端存储中都没有命中,从而导致大量的请求流向后端存储,增加了系统的负载和响应时间。
主要原因是恶意用户或者系统错误导致大量查询缓存中不存在的数据,这样的请求会绕过缓存,直接访问后端存储,导致后端存储的压力增大。
为了应对缓存穿透问题,可以考虑以下方法:
- 缓存空值: 即使数据不存在,也在缓存中存储一个特殊值,表示这个数据不存在。这样,在下一次请求同样的数据时,就可以从缓存中快速判断数据不存在,而不会再次访问后端存储。
- 使用布隆过滤器: 布隆过滤器可以用来快速判断某个数据是否存在于缓存中。如果布隆过滤器判断数据不存在,就可以避免绕过缓存直接访问后端存储。
- 热点数据预加载: 针对系统中的热点数据,可以在系统启动时提前加载到缓存中,避免由于查询热点数据时导致缓存穿透。
- 限制请求频率: 可以在缓存层面限制同一个请求的频率,避免大量的恶意请求绕过缓存直接访问后端存储。
- 使用缓存云平台: 一些缓存云平台(如AWS Elasticache、Redis Labs等)提供了针对缓存穿透的解决方案,可以自动处理缓存穿透问题。
代码示例
这里的示例以我的用户是否浏览过记忆为例:
@Component
@RequiredArgsConstructor
public class UserViewedMemoryBloomFilterUtil {
private final RedisTemplate<String, Object> redisTemplate;
private static final String BLOOM_FILTER_KEY_PREFIX = "memory_bloom_filter:";
private static final double EXPECTED_INSERTIONS = 100000;
private static final double FPP = 0.03;
/**
* 判断某个用户是否浏览过某个记忆
*
* @param userId 用户ID
* @param memoryId 记忆ID
* @return true表示用户已经浏览过,false表示用户未浏览过
*/
public boolean hasViewedMemory(String userId, String memoryId) {
String bloomFilterKey = BLOOM_FILTER_KEY_PREFIX + userId;
long[] offsets = bloomFilterOffsets(memoryId);
byte[] bloomFilterBytes = (byte[]) redisTemplate.opsForValue().get(bloomFilterKey);
if (bloomFilterBytes == null) {
// 布隆过滤器为空,则用户一定未浏览过该记忆
return false;
}
// 判断该记忆是否在布隆过滤器中
for (long offset : offsets) {
if (!getBit(bloomFilterBytes, offset)) {
return false;
}
}
return true;
}
/**
* 将某个记忆标记为已浏览过
*
* @param userId 用户ID
* @param memoryId 记忆ID
*/
public void markMemoryAsViewed(String userId, String memoryId) {
String bloomFilterKey = BLOOM_FILTER_KEY_PREFIX + userId;
long[] offsets = bloomFilterOffsets(memoryId);
byte[] bloomFilterBytes = (byte[]) redisTemplate.opsForValue().get(bloomFilterKey);
if (bloomFilterBytes == null) {
bloomFilterBytes = new byte[getBloomFilterSize(EXPECTED_INSERTIONS, FPP)];
}
// 将该记忆对应的位设置为1
for (long offset : offsets) {
setBit(bloomFilterBytes, offset);
}
redisTemplate.opsForValue().set(bloomFilterKey, bloomFilterBytes);
}
/**
* 获取某个记忆在布隆过滤器中对应的位
*
* @param memoryId 记忆ID
* @return 位的数组
*/
private long[] bloomFilterOffsets(String memoryId) {
long hash1 = MurmurHash.hash64(memoryId.getBytes(StandardCharsets.UTF_8), 0, 0);
long hash2 = MurmurHash.hash64(memoryId.getBytes(StandardCharsets.UTF_8), (int) hash1, 0);
long[] offsets = new long[2];
offsets[0] = Math.abs(hash1 % getBloomFilterSize(EXPECTED_INSERTIONS, FPP));
offsets[1] = Math.abs(hash2 % getBloomFilterSize(EXPECTED_INSERTIONS, FPP));
return offsets;
}
/**
* 获取布隆过滤器的大小
*
* @param expectedInsertions 预期插入数量
* @param fpp 期望的误判率
* @return 布隆过滤器的大小
*/
private int getBloomFilterSize(double expectedInsertions, double fpp) {
// 根据预期插入数量和误判率计算布隆过滤器的大小
int size = (int) Math.ceil((-expectedInsertions * Math.log(fpp)) / (Math.log(2) * Math.log(2)));
return size;
}
/**
* 获取指定位置的位的值
*
* @param bytes 字节数组
* @param offset 位的位置
* @return 位的值,true 表示 1,false 表示 0
*/
private boolean getBit(byte[] bytes, long offset) {
// 因为一个 byte 等于 8 个 bit
int index = (int) (offset / 8);
// 得到在一个字节中的下标位置
int bitPos = (int) (offset % 8);
// 位运算,偏移 bitPos 下标位置的向量
byte mask = (byte) (1 << bitPos);
// 和数组中的对应位置的字节中的8位bit进行与运算,当该位置存在时即不等于0
return (bytes[index] & mask) != 0;
}
/**
* 将指定位置的位设置为 1
*
* @param bytes 字节数组
* @param offset 位的位置
*/
private void setBit(byte[] bytes, long offset) {
int index = (int) (offset / 8);
int bitPos = (int) (offset % 8);
byte mask = (byte) (1 << bitPos);
// 或运算,只有该位置不存在时才将该位置设置成1
bytes[index] |= mask;
}
}